Hardware Architecture¶
HW Accelerator Model¶
Multiple cores are combined together into the Stream accelerator object.
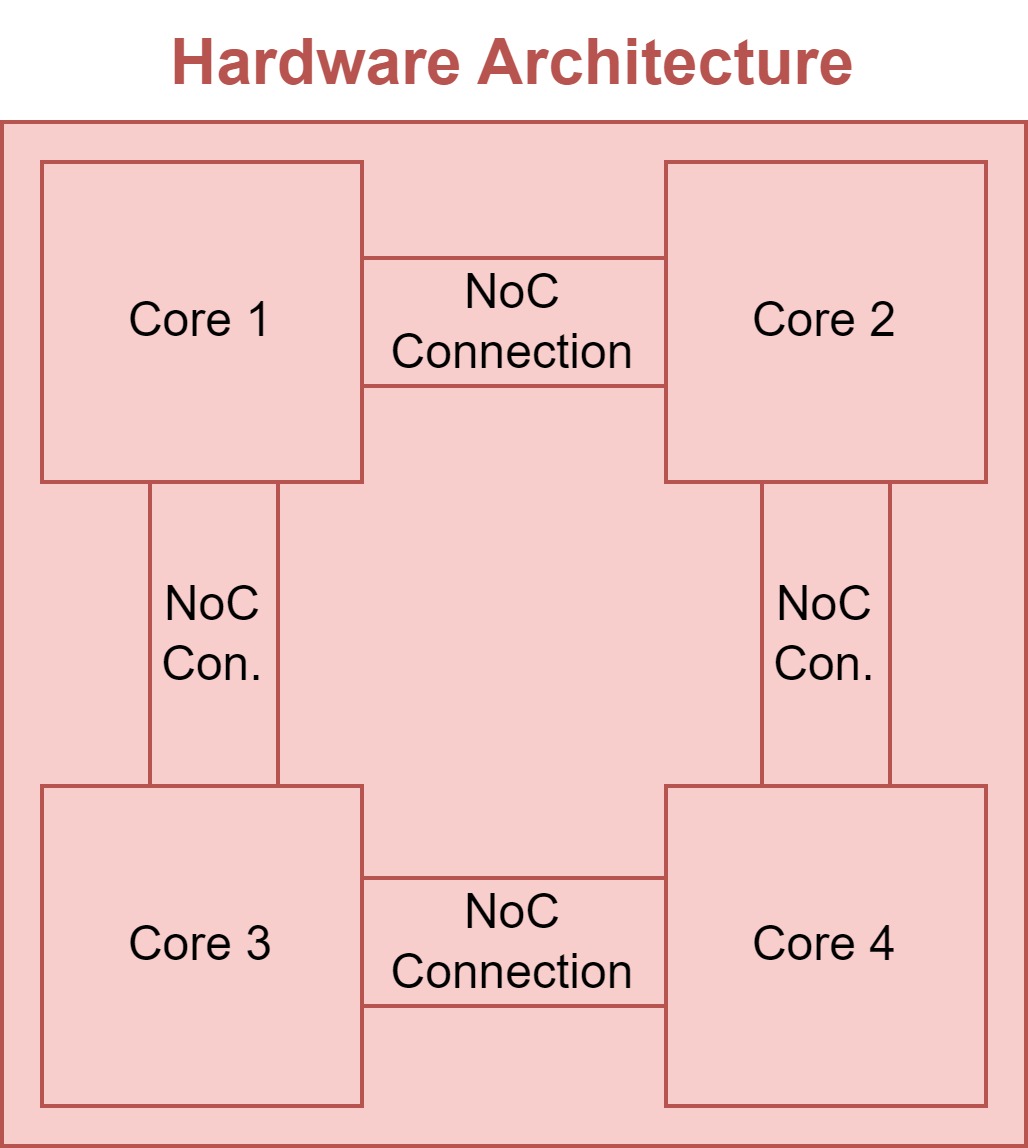
The Stream accelerator definition includes:
name: A user-defined name for the accelerator.
cores: A list of cores, each defined in a .yaml file. Absolute or relative paths are allowed. The standard path assumed is “./cores/”.
graph: Definition of the core interconnection topology.
Graph Definition¶
The graph definition determines the core interconnection topology. Currently, two topologies are supported: ‘2d-mesh’ and ‘bus’.
The ‘2d-mesh’ topology is defined through the following fields:
type: The type of the graph, which should be ‘2d-mesh’.
nb_rows: The number of rows in the 2D mesh.
nb_cols: The number of columns in the 2D mesh.
bandwidth: The bandwidth of each created directional link in bits per clock cycle.
unit_energy_cost: The unit energy cost of having a communication-link active. This does not include the involved memory read/writes.
pooling_core_id: If provided, the pooling core id. A link is added between the pooling core and each compute core in the mesh.
simd_core_id: If provided, the simd core id. A link is added between the simd core and each compute core in the mesh.
offchip_core_id: If provided, the offchip core id. A link is added between the offchip core and each compute core in the mesh.
The ‘bus’ topology is defined through the following fields:
type: The type of the graph, which should be ‘bus’.
bandwidth: The bandwidth of the bus in bits per clock cycle.
unit_energy_cost: The unit energy cost of having a communication-link active. This does not include the involved memory read/writes.
pooling_core_id: If provided, the pooling core id. A link is added between the pooling core and each compute core in the mesh.
simd_core_id: If provided, the simd core id. A link is added between the simd core and each compute core in the mesh.
offchip_core_id: If provided, the offchip core id. A link is added between the offchip core and each compute core in the mesh.
Modelled examples¶
Several examples about how to model the hardware architectures in Stream can be found here.